सदस्य:कन्हाई प्रसाद चौरसिया/प्रयोगपृष्ठ

 विक्षनरी परिचयसम्पादनहिन्दी विक्षनरी पर 15 अगस्त से 31 अगस्त, 2021 के बीच आयोजित की जाने वाली एक संपानोत्सव है। इसका मूल्य उद्देश्य हिन्दी विक्षनरी को बेहतर बनाना या बढ़ावा देना रहा है। अतः इस संपानोत्सव में आपका बढ़-चढ़कर हिस्सा लेना हिन्दी विक्षनरी को आगे बढ़ाने में मददगार साबित हो सकती है। नियमसम्पादनइस प्रतियोगिता में भाग लेने सम्बन्धित कुछ महत्वपूर्ण बिंदुए हैं जिन्हें आपको ध्यान रखना हैं-
सुझावसम्पादन
विक्षनरी सम्बंधित संक्षिप्त जानकारीसम्पादनयह पहली बार संपादनोत्सव का आयोजन होने जा रहा है। अतः नये सदस्यों के लिए विक्षनरी की संक्षिप्त जानकारी स्पष्ट कर देना बहुत ही आवश्यक हो जाता है। अक्सर लोग यह भ्रमवंश में पड़कर लेखों का निर्माण करने लगते हैं-
अपवादसम्पादनआपको यह कुछ बिन्दुए ध्यान रखने की जरूरत हैं-
अंक प्रणालीसम्पादनअंक प्रणाली की गणना सदस्यों के द्वारा योगदान के अनुसार निर्धारित किए जाएंगे। पुरस्कारसम्पादनप्रतियोगिता के कार्य के अनुसार चार प्रकार की पुरस्कार निर्धारित किए जायेंगे।
पुनरीक्षकसम्पादनप्रतिभागी अपना योगदान यहां जमा करेंसम्पादनप्रतिभागीसम्पादन
<translate> What do you want to do?</translate> सदस्य:कन्हाई प्रसाद चौरसिया<translate>This page describes categorization practices specific to Wiktionary as opposed to, say, Wikipedia. To find out about how to use categories in MediaWiki, the software that runs Wiktionary and Wikipedia, see Help:Category. Before you start to assign pages and subcategories to categories and create new categories, please check the conventions described in this page, and make yourself familiar with the categories already in use. Each page is typically in at least one category. It may be in more, but entries in topical categories should rarely—if ever—be put into a more narrow category and also a more general category. Each category should be in at least one higher-level category, except for the highest-level category: Category:Fundamental. For category names the usual rules for case-sensitivity of page names apply: they are case-sensitive for all characters, but in most projects the first character is case-insensitive. So be aware that you create a new category if the capitalization beyond the first character is not the same. All topical categories begin with a capital letter: there is "Category:Foods" rather than "Category:foods". However, the language-specific prefix such as "fr" in "Category:fr:Foods" is in lowercase. Main branchesसम्पादनThe root category of Wiktionary is Category:Fundamental. This category contains several main categories. Categories are used in Wiktionary for the following main purposes:
A complete dictionary entry will be in at least one, and usually in more than one, category. A word can also be categorized in many branches of the category tree, allowing it to be found in different ways. For example: mare is in the category Category:English nouns, as well as in the topic Category:en:Horses. It can quickly be found by readers looking for an English noun in particular. Likewise, 馬 is in Category:Japanese nouns as well as in Category:ja:Horses. Part of speechसम्पादनEach word should be in the appropriate category for language and part of speech. For example: mare is a word in English, Latin, Italian, and Romanian, and has sections for each of those languages. It thus belongs to language categories of each branch, specifically, Category:English nouns, Category:Latin nouns, Category:Italian nouns, and Category:Romanian nouns. The assignment of an entry to a part-of-speech category is usually done automatically by an inflection-line template, such as Parts of speech have the root category of Category:Lemmas subcategories by language, a subcategory of Category:Fundamental. The root category for parts of speech includes the category of Category:Nouns by language, which in its turn includes the category of Category:Russian nouns. Some terms are not strictly parts of speech, such as affixes, or only stand in for other terms that have, like acronyms. These terms have their own categories and are kept separate from the part of speech hierarchy. Languageसम्पादनThe Category:Fundamental contains Category:All languages, which in its turn contains categories named like Category:English language. Each language category contains subcategories for parts of speech, described in the section #Part of speech, and some other categories related to the language. Languages are also categorised by various other means, such as their relationship to other languages (Category:Languages by family), script (Category:Languages by script) or the places where they are spoken (Category:Languages by country). See also Wiktionary:Language categories. Topicसम्पादनWhere useful, words are categorized by topic such as "Animals" or "Chemistry". The root of topical categories is Category:All topics. This root category contains only some major subcategories, such as Category:Communication or Category:Sciences; further categories on a more fine-grained level such as Category:Horses are located somewhere else, deeper in the subcategory tree. There is also Category:List of topics, which lists all topics alphabetically no matter where in the category tree they are located. Each name of a topical category refers to the objects or meanings referred to by words that are members of the category; the name does not refer to the member words themselves. Thus, there is "Category:Chemistry" rather than "Category:Chemical terminology" or "Category:Chemical terms", or there is "Category:Animals" rather than "Category:Animal names". In other words, the names of topical categories denote what the terms are about, not what they are. Each name of a topical category has a prefix that indicates the language of the terms belonging to the category. Thus, the English category for horses is Category:en:Horses, while the Japanese one is Category:ja:Horses. The prefix consists of the language code followed by a colon. Names and subcategory structures of categories should be matched between languages. Thus, if Category:Horses is a subcategory of Category:Equids, then also Category:en:Horses should be a subcategory of Category:en:Equids. If there exists the category Category:fr:Cryptozoology, there should also exist the category Category:Cryptozoology. The subcategory structure of topical categories is technically maintained in "topic cat parents", such as Template:topic cat parents/Social sciences. This subpage tells the template "Names" are proper nouns, and are categorized by part of speech: Category:Japanese proper nouns Etymologyसम्पादनEach language that has terms for which the origin is known has a category of the form "Category:(language) terms by etymology". This category contains terms categorised by the way in which they first entered the language. This includes words that were formed with certain affixes or words that were formed by compounding them with another word, but also terms that have unusual or notable origins. The root of etymology categories is Category:Terms by etymology by language. In particular, languages that are known to have acquired some of their words from other languages have a subcategory named "Category:(language) terms derived from other languages", such as Category:English terms derived from other languages. Languages that in turn are the source of words in other languages have a subcategory named "Category:Terms derived from (language)", for example Category:Terms derived from English. This category lists non-English words derived from English, rather than listing English words. When adding the etymology section to an entry, please categorize the word into the appropriate derivation categories, using templates such as Style of usageसम्पादनMany words in a language are not used in all situations, or have certain connotations that are not obvious. This style of usage categorized under Category:Terms by usage by language, with a category for each language. This category contains subcategories for terms that are stilted or formal, old-fashioned, offensive, humorous and so on. Purposes internal to Wiktionaryसम्पादनCategories such as the following are special categories used for maintenance purposes, and reside outside of the main category tree:
In addition, many templates are used on Wiktionary to help in creating and maintaining entries. These are located under Category:Templates. Many languages also have templates that are specific to that language, which are contained in categories such as Category:English templates. Category browsingसम्पादनCategories only list 200 entries at a time. This can be an inconvenience to the user when a category contains more than 200 entries. To alleviate this, add an A-Z table of contents to the category by editing the category page and adding {{CategoryTOC}} to it. 4==Wiktionary:Discussion rooms== Wiktionary > Discussion rooms
For discussion
For monitoring
Further Information
If you want to chat with other Wiktionary users, you may find some of them at #Wiktionary. Feel free to pop in and say hello; there is normally someone who will answer. If no-one does, it is probably because they are all away or asleep. Remember that everyone is in different timezones, so try again after a couple of hours. In order to access these channels, you will need an IRC client. Some of the more popular ones are ChatZilla and mIRC, though there are many others. If you don't wish to install a client, then you can get to the channels through webchat.freenode.net #wiktionary-gfdl has its logs published under the GFDL and so discussion there should remain on topic. Often, if a discussion on #wiktionary seems to be getting important and involved, the participants will migrate to #wiktionary-gfdl so that they can refer to the discussion, should the need to arise later. See alsoसम्पादन6 ==Wiktionary:Languages==
Wiktionary includes many words in many languages. This page details the conventions and practices relating to the variety of languages on Wiktionary. Criteria for inclusionसम्पादनLanguage informationसम्पादनTo distinguish languages, Wiktionary gives each a unique name and a unique code, which identify it. Other information is also collected. Language namesसम्पादनWiktionary calls each language it includes by a distinct name. This name is used in headers, translation tables, categories, appendices, and some other places. Most languages only have one name, but some may be known by multiple names. In this case, one of the language's names is chosen for use in Wiktionary. This name is referred to as the canonical name of the language. Canonical language names are chosen by consensus. Whenever possible, common English names of languages are used, and diacritics are avoided. Attested names (names which meet WT:CFI) are strongly preferred. Canonical names must be unique, meaning that a name must refer to at most one language. When two or more languages are commonly known by the same name, Wiktionary distinguishes them by choosing different canonical names for each one, using a variety of means:
Language codesसम्पादनEach language on Wiktionary also has a unique code assigned to it, usually consisting of two or three letters. This code is used to identify languages when including templates in entries. Language names are not used in this case because they are longer and less precise, as the above section illustrates. Topical categories also use the language code as part of their names. The list of standard language codes can be found at Wiktionary:List of languages and a the list of special language codes, including etymology-only languages, can be found at the subpage Wiktionary:List of languages/special. Wiktionary chooses codes for languages as follows, in order of priority:
Not all lects which have been assigned codes by the ISO are assigned codes or included by Wiktionary. This is the case for some constructed languages, for example. There are also many lects which the ISO has assigned codes which are not treated as distinct languages on Wiktionary. For example, the ISO assigned Moldovan/Moldavian the 639-1 code Mismatch with Wikimedia codesसम्पादनIn a small number of cases, there is a mismatch between the (typically ISO-derived) code used by Wiktionary to represent a language and the code used by the Wikimedia Foundation. For example, Aromanian is represented on Wiktionary and in ISO 639-3 by the code Language familiesसम्पादन
Wiktionary sorts languages into families. Most families are related through descent from a common ancestor, but a few are merely categories, such as "creoles and pidgins". Wiktionary records which family a language belongs to in the data modules of Module:languages. Like languages, families are represented by unique codes and have unique canonical names.
Some languages are not naturally descended from other languages, but show other origins. These use special types of families:
Scripts used by a languageसम्पादन
Wiktionary records which script(s) (writing systems) a language is written in as well. This information is primarily used by modules to be able to automatically detect and format non-Latin-alphabet text appropriately. Scripts, too, have unique codes and canonical names.
Finding and organising terms in a languageसम्पादन
Every language has a main category which contains all terms that the English Wiktionary has for that language. This category is named using the canonical name of the language, followed by the word "language". For example, the main category for English is Category:English language. If the canonical name of the language already ends in the word "language", nothing is added (hence Category:American Sign Language). The main category for a language will have a variety of subcategories, which organise terms in various ways. The most important is the "lemma" category tree, which organises all lemmas in a language by their part of speech. As Wiktionary is always being expanded and improved upon, not all languages have their own categories yet, and certain subcategories may still be empty or missing. Categories are created as needed, when new entries are added to them. When content is added in a language lacking a category, it can simply be created using the Languages generally also have a page which contains information that is useful to users who want to create or edit entries in that language. This page is named "Wiktionary:About (canonical name of language)", for example Wiktionary:English entry guidelines or Wiktionary:About Spanish. These pages contain a wide variety of information, depending on what other editors have found useful to note. They may explain which templates to use, specific conventions regarding spelling, pronunciation or transliteration, and more. By convention, a shortcut redirect is created to these pages for easy access, named WT:A(language code). For example, WT:AEN redirects to Wiktionary:About English (for which the code is Storing and retrieving language informationसम्पादन
Templates and modules use a system for storing and retrieving the various pieces of information that may be associated with a language. The module Module:languages is used to retrieve all language-related information from other modules. This module cannot be used directly in a template, so instead there is another module named Module:languages/templates, which allows templates to access the information. An overview of all basic information about a language, such as its canonical name, alternative names, code, family or scripts, can be looked up at Wiktionary:List of languages (or WT:LL for short). This is useful if you need to look up the code for a particular language, or need to know what the canonical name of a language is. The data itself is not stored in Module:languages, but instead is contained in a number of data modules (see Category:Language data modules). These are organised as follows:
7 ==Wiktionary:Policies and guidelines==
Wiktionary is a collaborative project and its founders and contributors have common goals. Wiktionary policies and guidelines help us to work toward those common goals. These policies are continually evolving, and need some effort to maintain their evolution. You can contribute to the effort. Key policiesसम्पादनYou don't need to read every Wiktionary policy before you contribute! However, the following principles are key to a productive, collaborative Wiktionary experience, and should always be borne in mind.
A former alphabetical list of policies was at Wiktionary:Index to Policies, but is no longer maintained. How are policies decided?सम्पादनWiktionary policy will be formulated for the most part by consensus. Consensus can be reached through open debate over difficult questions, or it may simply develop as a result of established practice. The statements on this and other pages about Wiktionary policy are intended to describe community norms that are developing over time.
Policies that result from established practice are sometimes harder to identify. If there is no objection to the practice, it may be difficult to sustain community attention long enough for a formal process of adopting it as policy. In this situation, the best solution may be to document existing practice on a language's "About" page (see here the "About" page for Latin, as an example) if necessary. How are policies enforced?सम्पादनYou are a Wiktionary editor! Wiktionary has no editor-in-chief or any central, top-down mechanism whereby the day-to-day progress on the dictionary is monitored and approved. Instead, active participants add new articles, improve others, and make corrections to the content and format problems they see. So the participants are both writers and editors. Most policies and guidelines are thus implemented by individual users editing pages, and discussing matters with each other. There are some administrators appointed that will tackle the problems of vandalism and housekeeping, for which they need extra privileges. Anyone with a fair track record of contributions can apply for administrator status. For instructions on how to edit this information, see the documentation of any of the data modules. 8 ==Wiktionary:Picture dictionary==
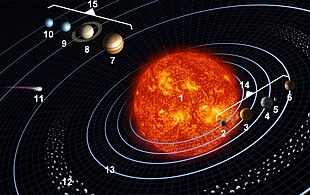
Purposeसम्पादनCreate a database of visual lexical entries comprising all words and expressions in common use, in all languages. This database must be readable both by humans and computers, so that it may be used by language learning applications, such as flashcards and other. Justificationसम्पादनThere are many words that cannot be properly conveyed by their description or translation alone. Additionally, visual representation greatly reinforces assimilation. The Picture Dictionary is of special interest for those interested in "translation-free" language learning. Translation-free language learning is still a self-defeating endeavor nowadays, due to the fact that there is no practical way for a beginner student to find out the meaning of a new word without relying on bilingual dictionary. We already have a huge image bank at Wikimedia Commons that could be incorporated on this project in a partially automated way. This project could also be used to add missing images to Wikipedia articles and to illustrate the main Wiktionary entries. Tasksसम्पादन1 - Create thematic lists of vocabulary entries. This would be best done by using the Wiktionary category list, but if it's not found to be adequate, it should be improved based on other sources, such as the main Wikipedia categories, Wordnet, and other works. 2 - Select the relevant entries by accessing their frequency. This can be done by using a frequency list, searching within a corpus, or a web search. 3 - Get some representative pictures from Wikimedia Commons, upload if necessary. For added cultural authenticity the picture should from a place where the language is primarily spoken, if available. But missing pictures should be added from the English picture list until a better one is found. Templates usable in four different waysसम्पादनOver the past days I created a few templates that can be used to build a Picture dictionary in 4 different ways. The templates are Four different ways to use Template:picdic: Solar System examples with comparable links. See also Template:picdic#Examples for these examples with coding as well.
What can be improved in these templates? I am not 100% pleased with the way to add clickable image(s) describing a hypernym of the entry. Any suggestion is welcome. HenkvD 18:13, 15 July 2010 (UTC) See alsoसम्पादनSubpagesसम्पादन9 ==Wiktionary:Shortcut== Compact list of shortcuts usedसम्पादनThis list is a trimmed-down one of main shortcuts. There is also a generated list. A large number of shortcuts are like WT:AEN => Wiktionary:About English where "WT:A" is followed by a two- or three-letter code for a language. What is a Wiktionary shortcut?सम्पादन“Shortcuts” in Wiktionary, derived from their counterparts in Wikipedia, are a specialized type of redirection page that can be used to get to a commonly used Wiktionary reference page more quickly. How to use Wiktionary shortcutsसम्पादनA Wiktionary shortcut can be be entered into the Wiktionary search box to quickly bring you to a reference page. Alternatively, you can use the shortcut in the URL (web address). For example, you are currently viewing the Wiktionary:Shortcut page in English. The URL is Shortcuts are presented in all capital letters (“All-Caps”), but the search box is case-insensitive. For example, in the search box, you can type “wt:bp” instead of “WT:BP”. However, using the URL method typically requires that you match the capitalization of the shortcut. Adding shortcut link boxes in the destination pagesसम्पादनYou can add a “shortcut link box” in a shortcut destination page, in order to educate the users about the shortcuts available.
A shortcut link box (the “shortcut template”) is added to the entry source (“Editing” page) using 10== Wiktionary:Templates== A template is a page in the Template: namespace, which contains special wiki code that allows it to be reproduced ("transcluded") on== many different pages. Templates can either be transcluded directly, or you can pass on additional information (through "parameters") to the template that controls or modifies its behaviour. The advantage of using templates is that when the template itself is changed, all pages that transclude the template will automatically be updated as well. This helps in reducing the duplication of identical content, and templates are a powerful tool for keeping the appearance of certain parts of a dictionary entry consistent. For example, a single template to generate a table of inflected forms of a verb can be used on hundreds of different pages, but will look and function the same on each one. Generally speaking, if you find yourself having to add more or less the same thing on several pages, it's probably better to write a template instead and transclude it onto the pages. Wiktionary makes heavy use of templates, so it is a good idea to familiarise yourself with how they work and how to use them, even if you don't write your own. Templates can be found in Category:Templates and its subcategories. Writing templatesसम्पादनTemplates may either use a Scribunto module as underlying mechanism, or be written directly in template code. Although Scribunto is strongly preferred for templates with complex logic, a straightforward string-assembly template probably doesn't need a module. Some templates may also mix both, calling on Scribunto for some parts while using template/wiki code for the remainder. Here are some good guides for using and writing templates:
If you want to create a new template, but you're still inexperienced with them or with Wiktionary in general, it's probably best to ask first (at the WT:Grease Pit). Maybe there isn't really a need for such a template, because the problem you are trying to solve with it can be approached differently. Maybe someone else already wrote something similar to your idea; it would be better to use what already exists instead of doing it all over again. For that reason, the best way to "learn" templates is probably to study the ones we already have on Wiktionary. Language-specific templatesसम्पादनMany languages have their own set of templates, which can be found in one of the subcategories of Category:Templates by language. Language-specific templates are better able to cater to the needs of a specific language than a general template can, and allow for specific exceptions or restrictions that general templates don't. Because they are made for a specific language, knowledge of that language's grammar can be embedded into them. For example, the template While it may be easier to use generic templates like Naming templatesसम्पादनTry to use a name that is both short and descriptive. As a rule of thumb, the more often the template will be used, the more leeway there is in using a short name. Templates that are used only within other templates should have longer names, as they generally don't need to be used that often. If you can, try to avoid using characters outside the ASCII encoding (use only the Latin alphabet), so that everyone can easily type the template's name. Templates that are intended specifically for one language should have a name that begins with that language's language code, followed by a hyphen. For example, By convention, usage-note templates have names beginning with U:, followed in most cases by a language code and then another colon, and then a short, descriptive name; for example, Template:U:en:less and fewer. (A small number of usage-note templates may be applicable across multiple languages and may omit the language code.) Reference templates have names beginning with R: (optionally followed by a language code and then another colon) and then a short, descriptive name; for example, Template:R:mia:Costa:2003 or Template:R:Etymonline. Changing existing templatesसम्पादनSpecial care should be taken when making changes to an existing template, since the changes will (potentially) affect all pages that transclude the template. Depending on the editing interface you are using, you should be able to preview your changes before publishing them (in the standard editor the relevant features are called "Show preview" and "Show changes"). You may also be able to preview (before publishing) how another page that calls the template you are editing will look once your changes are applied ("Preview page with this template"). Most of our templates can be modified by any user, but sometimes templates are protected from editing by regular users. In such a case, proposed changes can be discussed on the template's associated discussion page or in Wiktionary:Grease pit to gain consensus before requesting that the changes be made by a template editor. Showing a link to the template page and documentationसम्पादनTo display a link to a template page presented in the style of a call to that template, you can use:
For example:
produces:
where you can follow the link to see how to use the "quote" template. This is useful in discussions and in template documentation, but should not be used in our dictionary entries. Headword-line templatesसम्पादनमुख्य श्रेणी: Headword-line templates by language
Headword-line templates are templates that are used to produce the headword line of a term. (historical note: this was formerly called the "inflection line", and headword-line templates used to be called "inflection templates") The headword line is the line that comes immediately below the header specifying the part of speech (such as Noun or Verb). At the very least, the headword line contains the headword in question, specially formatted in bold text. Additional information may also be presented on the headword line, such as the gender of a noun (for languages where that applies), or a selection of inflected forms. Most languages have their own set of headword-line templates; these are the most common form of language-specific template. In cases where the language lacks an appropriate headword-line template, Namingसम्पादनHeadword-line templates are named using the language code, followed by an abbreviated form of the part of speech that the template is used for. For example,
Languages may extend these names if they need templates for more specific purposes, such as Formatting the headwordसम्पादनThe headword itself appears in boldface, unless it's in a writing system where bold text is harder to read, in which case it appears with a larger font-size (this is controlled through MediaWiki:Common.css). Within the template's code, the There are a few different ways that headword lines have been created in the past using a template. Not all of them should be used anymore, but you may encounter such code in older templates and entries that have not been brought up to date.
Genders and other grammar informationसम्पादनFor languages that have grammatical genders, the gender usually immediately follows the headword. Genders should be formatted using Module:gender and number or through It's usually good coding practice to add code to the template that checks whether the gender that has been provided to the template is valid. For example, French has no neuter gender, so if someone writes Inflected and related formsसम्पादनFollowing the headword and optional gender information, you can choose to display additional forms of the word, surrounded by parentheses. When displaying and/or linking to forms in the template, you can either use a generic linking template like (''plural'' <b lang="nl">[[woorden#Dutch|woorden]]</b>, ''diminutive'' <b lang="nl">[[woordje#Dutch|woordje]]</b>)
(''genitive'' <span lang="sl">'''[[besede#Slovene|bésede]]'''</span>)
(''simplified'' <b lang="cmn" class="Hani">[[马#Mandarin|马]]</b>, ''pinyin'' <b lang="cmn-pinyin">mǎ</b>, ''Wide-Giles'' <b lang="cmn-wadegile">ma<sup>3</sup></b>)
A template may need additional parameters to correctly display the additional forms, while some forms can be determined automatically. Different templates currently use different approaches. Be very mindful of which forms you choose to include in this way. While a lightly-inflected language like English only has a few forms, languages like Latin may have dozens, and they could never fit onto a single line (also keep in mind that some users might have smaller screens!). If a word in your language has too many distinct forms to fit on one line (4–5 is probably about the limit) then it's better to show either no forms on the headword-line, or show only a few key forms that help users figure out the remainder themselves. For Latin verbs in particular, the four verb forms that are displayed on the headword line are the least predictable forms, which most other forms can be regularly derived from (so-called "principal parts"). Categoriesसम्पादनIt is generally expected that every headword-line template will add the entry to a category corresponding to its part of speech. Inflection-table templatesसम्पादनमुख्य श्रेणी: Inflection-table templates by language
Languages that use several different forms of the same word often use inflection-table templates. These are templates that display a table or list containing all or most of the inflected forms of a particular word. Unless they are very small, these tables should be made collapsible, by enclosing them in the following code: <div class="NavFrame">
<div class="NavHead">(text to display when the table is collapsed)</div>
<div class="NavContent">
(put the table itself here)
</div>
</div>
By convention, tables that show the forms of nouns, pronouns and adjectives are named If a language needs at least two different templates for different inflectional classes of the same type of word, then it is considered good practice to create a third template, with the name ending in Form-of templatesसम्पादनOn Wiktionary, a form-of entry is an entry for a word that is considered an inflected form of another word. Such entries don't contain a full definition. Usually the definition is a short description of the grammatical properties of this form, and a link to the main entry. Compare, for example, the entries for locate and its past-tense form located. The definitions of such entries are generated automatically with templates. There is a wide variety of form-of templates, and many of them not specific to one language but can be used for most languages. For that reason, it is often not necessary to create form-of templates for your language. It doesn't hurt to do so anyway, but it may be considered wasteful and redundant if your template does what a generic template already does perfectly. Some form-of templates also add the entry to a category. Context label templatesसम्पादन(please expand)
Examplesसम्पादनCategory boilerplate templatesसम्पादन(please expand) Citationsसम्पादनTemplates for entering quotations (also Category:Citation templates):
Templates for referring to sources in quotations:
Columnsसम्पादनLong lists of terms (such as derived terms or translations) usually look better when formatted into columns. The templates below provide an easy method of doing this. Current Wiktionary style is to put such material in collapsible tables so that the user can display it only if they wish to. This makes an entry easier to read and navigate. Alternatively, content may be made permanently visible. It is preferable to use collapsible tables for long lists and to make only short lists permanently visible, or to use collapsible tables for all lists (given that short lists may eventually become much longer). To use any of these templates, place the "top" template immediately before the content and the "bottom" template immediately after. Place the "mid" (or "mid2") template as close to halfway through the content as possible. If using the templates for more than two columns, place a "mid3" template at one-third and another two-thirds of the way through the content, or the "mid4" at one-quarter, one-half and three-quarters of the way through. Use the templates from one group only at any one time. Do not combine templates from different groups, as this will give odd results or might not be parsed correctly by the browser. For "Translations" sections The following templates display translations in two columns in a collapsible table for the translations sections. They are for use only in the Translations section of an article; in other sections, use the templates below. The "trans-top" template takes an argument that is used as the header for the table. A gloss summarising the meaning being translated is put here. For example, in the entry for time, the gloss "inevitable passing of events" is given in the first table of translations, and this is generated thus: {{trans-top|inevitable passing of events}}.
Currently, templates for collapsible translation tables are available only in two-column format. For other lists Collapsible tables The following templates display lists in two columns in a collapsible table. They are for use in sections other than the Translations section of an article (not just the Related terms section, despite the name); in the Translations sections, use the templates above. The "rel-top" template takes an argument that is used as the header for the table. A gloss summarising the content of the table. For example, in the entry for time, the table of derived terms has the header "terms derived from time", and this is generated thus: {{rel-top|terms derived from ''time''}}. Note that this is the preferred format of a gloss for derived and related terms (which would have the header "terms related to time"). Note that the word or phrase which the terms are derived from or related to is italicised.
Very long lists can be formatted in four columns using the following:
where {{rel-mid4}} is to be used three times within the content to separate it into four columns of equal or approximately equal length. For lists that are always displayed Alternatively, a list of terms can be formatted so that it is always displayed (that is, not hidden in a collapsible table). This format is best reserved for short lists. The following templates display content in two, three or four columns. They are not for use in a Translations section of an article; in the Translations section, use
Etymologyसम्पादनEtymology templates:
Languages: These templates "wrap" the language abbreviations used in Webster 1913 (see Wiktionary:Abbreviations in Webster#Languages). One function of these templates is to make transcribing etymologies from Webster 1913 simple. Another function is to expand the obscure abbreviation into the full name of the language. A third function of these templates is to automatically categorize words according to their etymologies (see Wiktionary:Categorization). These templates will automatically both add a word to an etymology category and create an interwiki link to the language article on Wikipedia, as well as expand to the name of the language, and are suitable for use in the "Etymology" section of an article. 11 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||